Demystifying GRPO Objective: A Closer Look at Group Relative Policy Optimization
In this post, I am going to shed some light on Group Relative Policy Optimization (GRPO), proposed by Shao et al. (2024). The main motivation for discussing this method is its use in recent advancements in Large Language Model (LLM) alignment, specifically in DeepSeek-R1.

Essentially, this objective function aims to maximize the expected advantage of the new policy, encouraging it to generate outputs that are relatively more advantageous than those produced by the old policy for a given input.
Now, let’s define the ingredients of the formula:


This part is centered around a ratio (rt) that represents the probability of an output given a question under both the new and old policies. This ratio grows when the advantage is large and positive, meaning the probability of output i given q under the new policy should increase, and vice versa. This is the core idea.
However, the statement consists of two components:
- The first term multiplies rt by the advantage for each output.
- The second term clips rt around 1 using an epsilon value and then multiplies it.
On top of these, a minimum function ensures that the smaller value is selected, preventing overly large updates. But why do we need the minimum?

Here, we observe the unclipped objective, which is essentially the multiplication of rt by the advantage, for both Advantage=−1 and Advantage=+1, with varying ratios.
It is evident that increasing rt with a positive advantage increases the objective, while increasing rt with a negative advantage decreases the objective.
Now, let’s apply clipping. We set ϵ=0.2.

This clearly prevent from large updates out of the epsilon. when rt is 1 and the Advantage is positive, we have a positive objective, but in reverse there is negative. The clipping helps prevent the new policy from deviating too much from the old policy by ensuring that the rt is bounded between 1−ϵ and 1+ϵ. This avoids drastic updates that could harm the performance of the policy. Now we apply the minimum to see the effect:
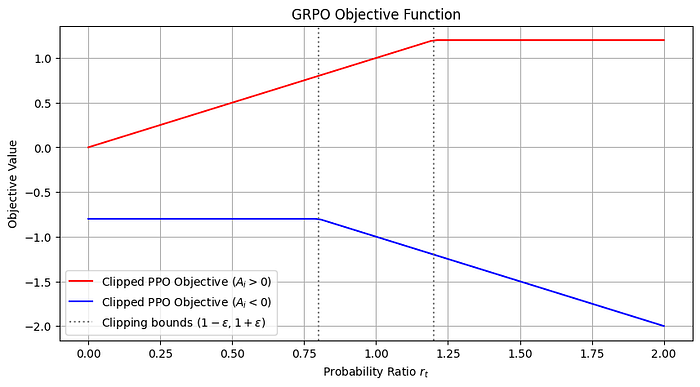
From the PPO paper: “Finally, we take the minimum of the clipped and unclipped objective, so the final objective is a lower bound (i.e., a pessimistic bound) on the unclipped objective. With this scheme, we only ignore the change in probability ratio when it would make the objective improve, and we include it when it makes the objective worse.”
Now, let’s focus on the regularization part of the formula:
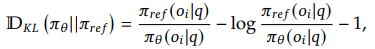
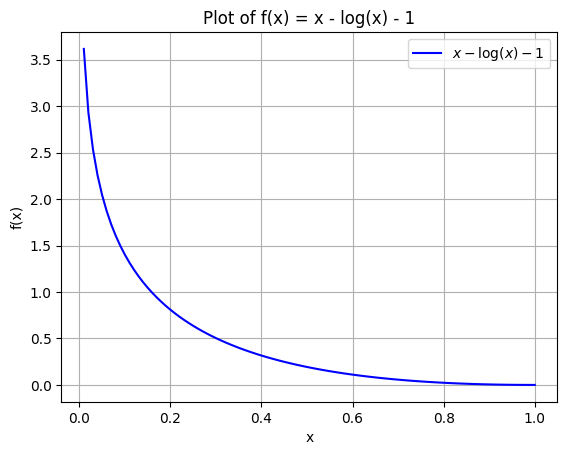
This is a positive value, and when rt=1, there is no regularization. Next, let’s examine its behavior:
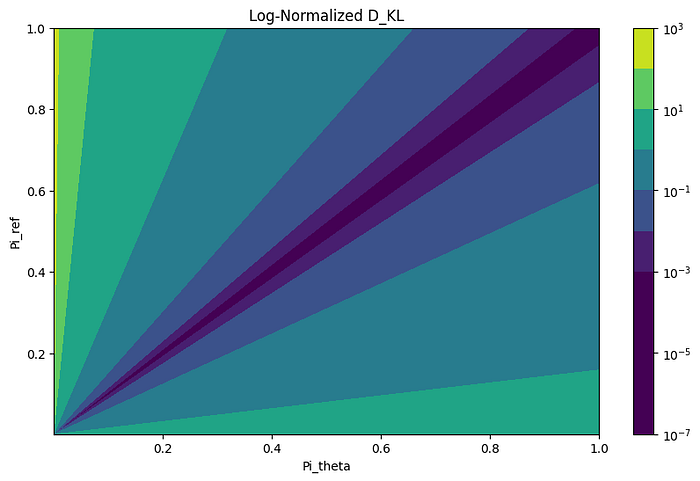
First, we observe that when the values are similar, the KL divergence decreases, which appears along the diagonal. Second, the term is more sensitive to large values of πref relative to low πθ than in the reverse case. This is where learned values in LLM training are suppressed through alignment.
References
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., … & He, Y. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., … & Piao, Y. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., … & Guo, D. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.